Introdução
Nos últimos anos, o Airbnb transformou a forma como viajamos e nos hospedamos. Lisboa, uma das capitais mais visitadas da Europa, possui milhares de acomodações listadas na plataforma. Mas o que os dados podem nos contar sobre esse mercado?
Neste artigo, apresento uma análise exploratória baseada em dados reais do Airbnb, revelando padrões de preços, tipos de imóveis, disponibilidade e até insights para quem deseja investir ou anunciar na cidade.

Objetivos da Análise
– Explorar a distribuição dos preços das diárias.
– Comparar os tipos de acomodações e seus valores médios.
– Identificar os bairros mais relevantes em termos de oferta e disponibilidade.
– Avaliar quais fatores têm maior impacto no preço.
– Testar a possibilidade de **prever preços com base em características dos imóveis**.
Metodologia e Ferramentas
Para este estudo utilizei um conjunto de dados público disponível no Kaggle.
📌 Principais ferramentas utilizadas:
– Python
– Pandas / NumPy (manipulação de dados)
– Matplotlib / Seaborn / Plotly (visualizações)
– Scikit-learn (modelagem preditiva)
– Folium (mapas interativos)
– Streamlit (dashboard interativo)
📌 Principais Descobertas
– 💰 Distribuição de Preços: a grande maioria das diárias está abaixo de €1500, com alguns outliers representando imóveis de luxo.
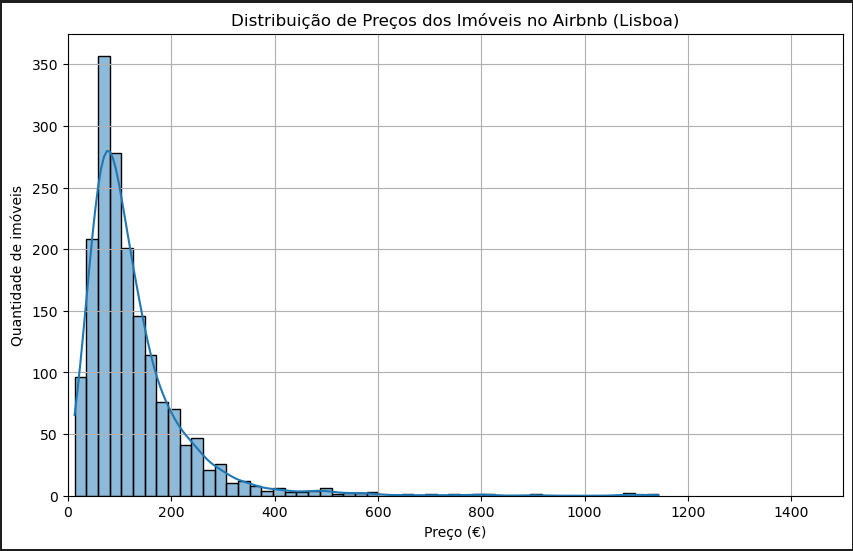
– 🏠 Tipos de Acomodações: apartamentos inteiros têm preços médios bem mais altos que quartos privados ou compartilhados.
– 📍 Oferta por Bairro: alguns bairros concentram muito mais imóveis, indicando regiões de alta procura e competitividade.
– 🔍 Correlação Entre Variáveis: tipo de imóvel e localização se destacam como fatores mais relevantes para explicar o preço.
– 🤖 Modelo Preditivo (Regressão Linear): apresentou resultados modestos, mas demonstrou potencial para uso de machine learning no setor imobiliário.
🤖 Modelos Preditivos Avançados
Evoluímos a análise inicial para algoritmos mais robustos:
– Árvore de Decisão (DecisionTreeRegressor)
– Random Forest (RandomForestRegressor)
📊 Resultados (comparados com a Regressão Linear):
– Random Forest apresentou melhor desempenho em R² e RMSE, conseguindo capturar variações complexas de preço.
– Isso mostra que técnicas de machine learning têm grande potencial no setor imobiliário para previsão de valores.
🗺️ Mapas Interativos
Visualizamos a distribuição espacial das acomodações em Lisboa com Folium
– Mapa de Pontos: cada imóvel aparece como um marcador colorido conforme a faixa de preço.
– Mapa de Calor: identifica regiões com maior concentração de imóveis e preços.
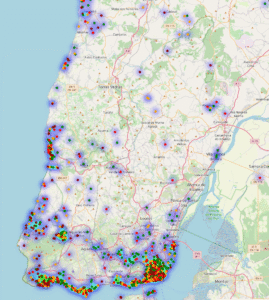
👉 Clique aqui para explorar o mapa interativo
📊 Dashboard Interativo
Para transformar a análise em um produto explorável, criei um **dashboard em Streamlit**:
– Filtros por bairro, tipo de acomodação e faixa de preço
– Histograma interativo da distribuição de preços
– Boxplot comparando tipos de acomodação
– Mapa interativo atualizado conforme os filtros
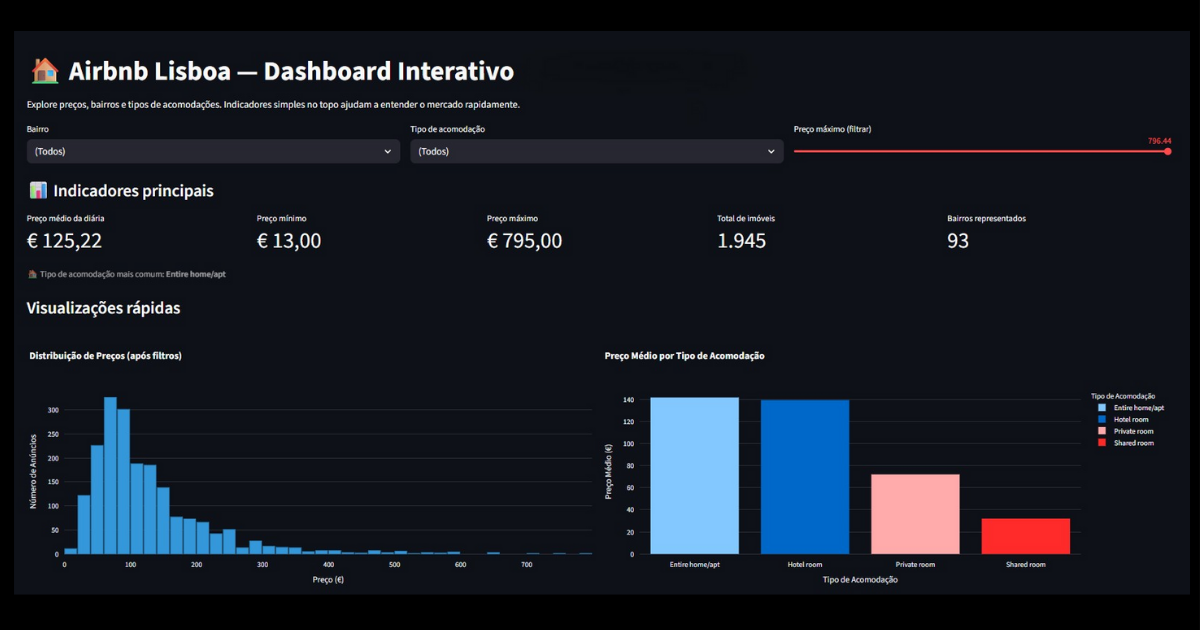
👉 Acesse o Dashboard Interativo
Conclusões
Lisboa apresenta um mercado de hospedagens dinâmico, com grande variação de preços e forte impacto do tipo de acomodação na precificação. Os dados evidenciam tendências que podem apoiar tanto turistas quanto investidores.
Além disso, a aplicação de algoritmos como Random Forest e visualizações interativas traz uma camada de inteligência ao estudo, aproximando a análise de um cenário real de apoio à decisão.
Próximos Passos
– Testar algoritmos mais avançados como **XGBoost** ou **LightGBM**.
– Integrar dados de turismo (ex.: fluxo de visitantes) para análises preditivas mais ricas.
– Publicar o dashboard em nuvem (Streamlit Cloud ou Hugging Face Spaces).
✍️ **Autor:** Lisandro Almeida Viana
📌 Este projeto faz parte do meu portfólio em Ciência de Dados. Conecte-se comigo no LinkedIn para acompanhar próximos estudos!